1要因の分散分析
概要
本ページ内では、1要因の分散分析を終着点とした一連の分析の手順についてまとめます。1要因の分散分析は、3つ以上のグループ間の平均値に差があるかを知るための分析手法です。ただ、その分析をするためには、通常、以下のような流れを踏む必要があります。
1.分析ソフトとデータの準備
2.変数の合成
3.記述統計
4.1要因の分散分析の実行
5.表の作成
6.論文の記述
まず、本コンテンツでは分析にHADを用いますので、それをダウンロードして使える状態にする必要があります(1:分析ソフトとデータの準備)。次に、心理学の研究では、多くの場合、複数の項目を使って1つの概念を測定することが行われます。そうした場合に、複数の項目を本当に1つの変数として扱っていいのかをチェックする必要があります(2:変数の合成)。さらに、重回帰分析の前に、それぞれの変数の平均値や標準偏差、相関係数をチェックし、それぞれの変数の特徴を記述します(3:記述統計)。ここまでが完了してようやく一番したい分析を実行することができます(4:1要因の分散分析の実行)。分析が終わったら、心理学論文の書き方に沿って、表をまとめ(5:表の作成)、文章で記述してください(6:論文の記述)。
1.分析ソフトとデータの準備
まず分析に用いるHADを使える状態にしてください。これがまだできていない方はこちらのページから準備をしてください。
次に、分析に用いるデータを準備し、HADに入力してください。Qualtricsで収集したデータを使われる方はこちらのページでやり方を確認してください。
ここでは刑事司法に対する態度(これについてはこちらのページをご参照ください)、犯罪不安、回答者の年代を含んだデータを分析に用います(実際のデータをもとにして、少し手を加えたデータです)。このデータはこちらからダウンロードできます。ご自身のデータがある方はそれを使ってください。
2.変数の合成
多くの心理学的な研究では、1つの構成概念を測定するために複数の項目を用意するといったことが行われます。今回のデータでも、厳罰傾向と犯罪不安はそれぞれ複数の項目で測定されています。
ただ、複数の項目が1つの構成概念をきちんと測定できているかは確認する必要があります。そのために用いられる統計的な手法は、①因子分析と、②信頼性係数(α係数)の確認です。どちらを使うかは先行研究で因子構造が確認されているかどうかによります。より端的には、自分で作成した尺度(項目)である場合や先行研究の尺度を変更した場合には因子分析を行う必要があります。これに対して、先行研究で用いられている尺度をそのまま使っている場合には因子分析をする必要はなく、信頼性係数を求めれば十分です。ご自身の計画がどちらに当てはまるかを確認してください。
なお、分析・判断は変数ごとに行う必要があります。たとえば、変数Aは先行研究のものをそのまま使っているが、変数Bは自分で新たに作成したものである場合には、変数Aは信頼性係数を求めるだけで足りますが、変数Bについては因子分析を行う必要があります。変数ごとに個別に判断してください。
ここで使われている変数(厳罰傾向と犯罪不安)は実際には先行研究で因子構造が確認されています(つまり、何個の因子に分かれるかはすでに示されています)。ですので、本来であれば因子分析をする必要はありませんが、あくまで例として因子分析も行っています。自分のデータを使って分析する方はご注意ください。
因子分析
まずデータを確認します。今回のデータでは、厳罰傾向を測定する項目は3個あり、cj_1からcj_3までの列に入力されています。因子分析ではこれらのデータを使いますので、これらをコピーして、「id」の横に貼り付けてください。

移動ができたら、「因子分析」にチェックを入れてください。
因子分析の前に、因子数を決める必要があります。「スクリープロット」を左クリックしてください。
「Scree」というシートが新たに作成されれば成功です。
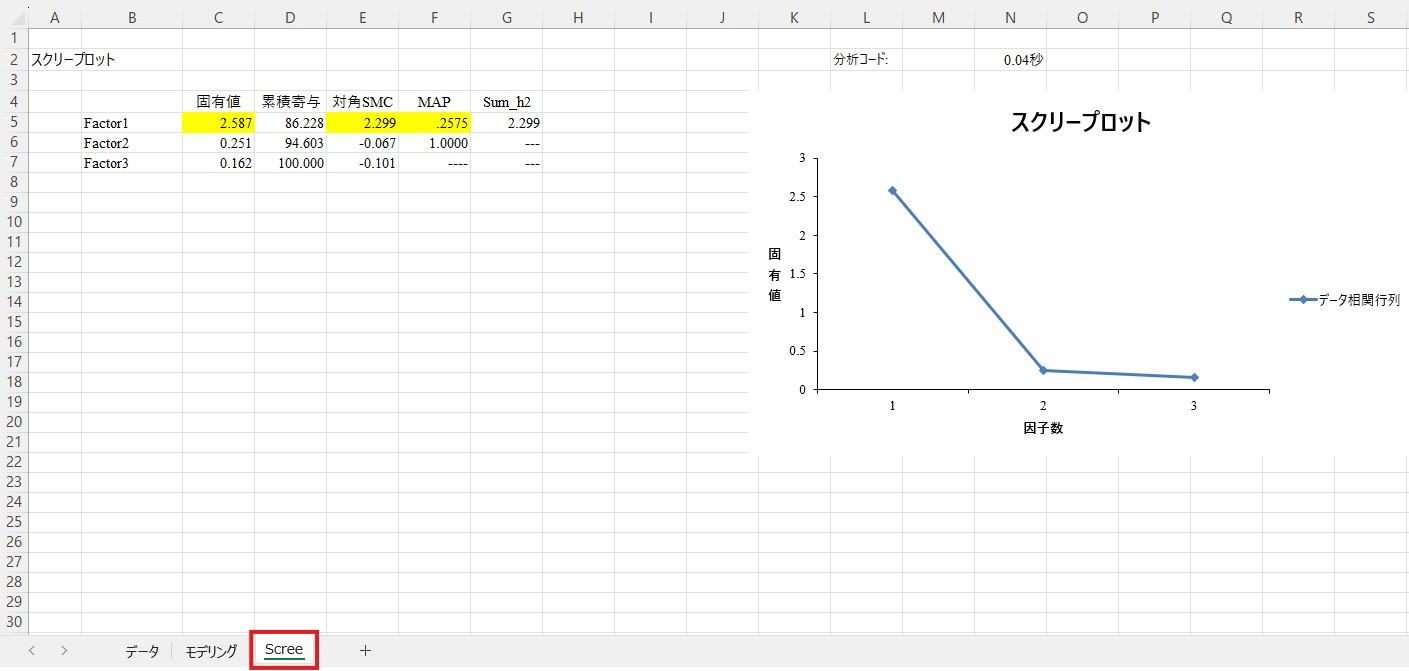
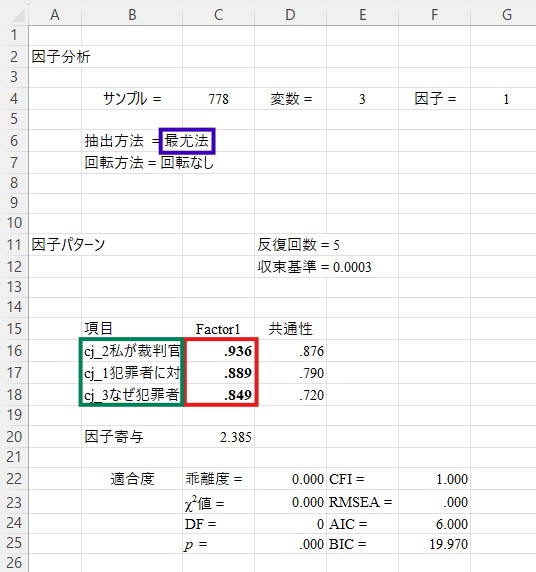
このシートには、固有値や累積寄与、対角SMCの値などが表示されています。これらの数値から因子数を決定する手法には色々なものがありますが、初学者の方にとっては固有値で色が付いている因子数を選択するのが最も楽かと思います。ここでは「Factor1」に色が付いていますので、1因子構造が妥当であると判断できます。
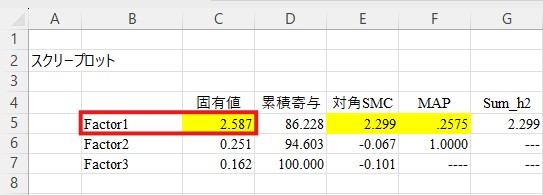
もう一度「モデリング」のシートに戻り、「因子数」に「1」を入力してください(必ず半角で入力してください)。

「分析実行」を左クリックしてください。

「Factor」というシートが新たに作成されれば成功です。
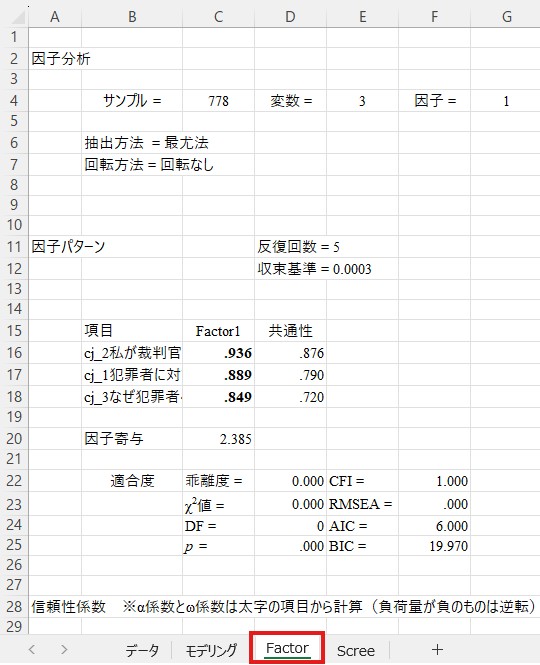
下の画像の赤で囲まれた部分が因子負荷量です。すべての因子負荷量が.400以上であるため、この因子構造で確定できます。
以上が1因子解の最もシンプルな因子分析ですが、因子が複数ある場合や因子負荷量が低い項目がある場合にはもう少し工夫をする必要があります。そのような場合にはこちらをご参照ください。
信頼性係数の算出
上記の通り、先行研究ですでに因子構造が分かっている場合には、信頼性係数を求めるだけで足ります。
まず信頼性係数を求めたい項目を「使用変数」にコピペします。ここでは厳罰傾向を測定する5つの項目の信頼性係数を求めたいという想定で、5項目をコピペします。

左上の「分析」を左クリックしてください。

表示されたポップアップ画面で、右上の方にある「項目分析(α係数)」にチェックを入れます。
右下の「OK」を左クリックしてください。
「Item」というシートが新たに作成されれば成功です。
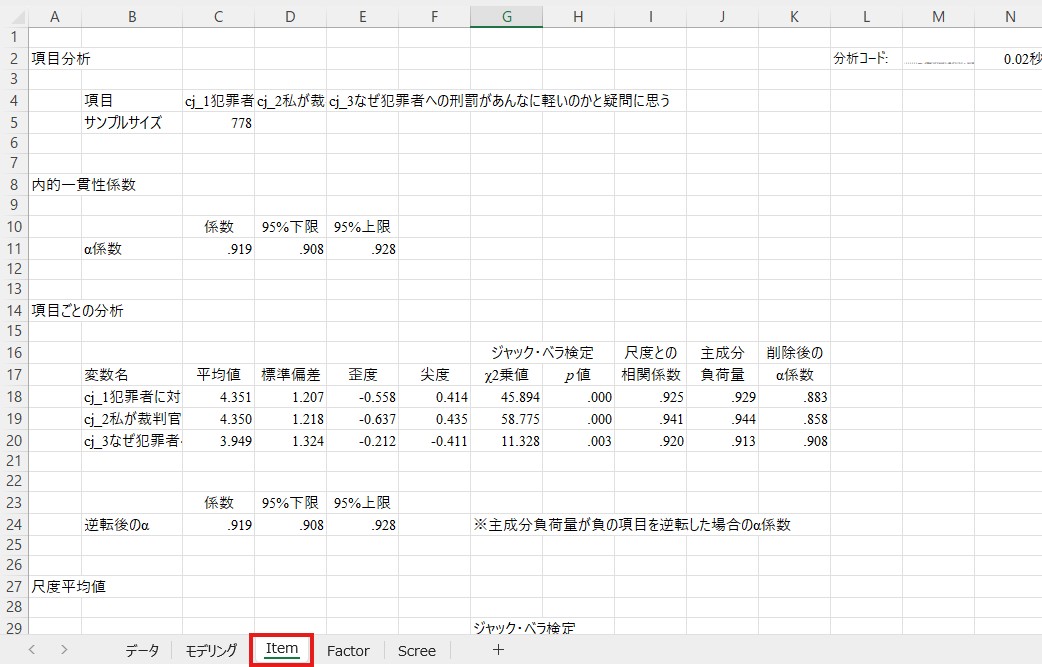
信頼性係数は上の方の「α係数」の横に表示されています。ここでは.864が厳罰傾向のα係数です。一般にα係数は.70以上であれば問題ないとされますので、ここでは特に問題はなさそうですので先に進みます。
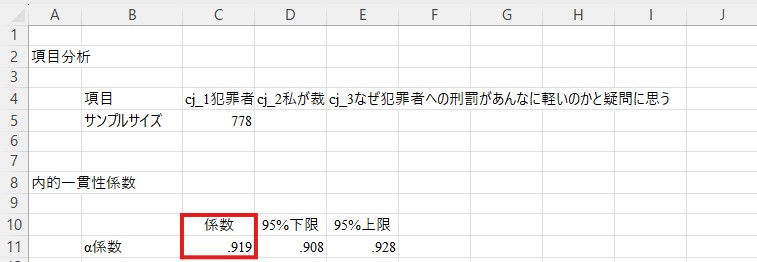
なお、尺度に逆転項目がある場合には、少し下の「逆転後のα」の値を使う必要があります(ここでは逆転項目は入っていませんので、上の値と下の値は同じになっています)。

合成変数の作成
ここまでで厳罰傾向を測定する5つの項目を1つの変数として扱っていいことが分かりましたので、次はこれらの5項目の平均値を算出し、それを厳罰傾向の値とします。合成変数の作成にはエクセルのaverage関数を使うやり方もありますが(関数を使ったことがある方にとってはおそらくそちらの方が通常楽です)、ここではHADの機能を使ったやり方を解説します。
まず合成したい項目を「使用変数」にコピペします(上と同じです)。

「変数の作成」を左クリックしてください。

表示されたポップアップ画面で、「平均得点を算出」にチェックを入れてください。
「OK」を左クリックします。
「Score」というシートが新たに作成されれば成功です。
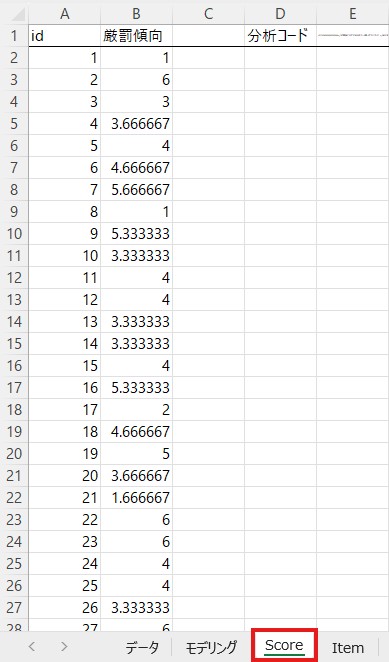
「Mean」の列には「使用変数」に入力した項目の平均値が入っています。ここでは5つの項目を入力しましたので、その5つの項目の平均値が計算されています。
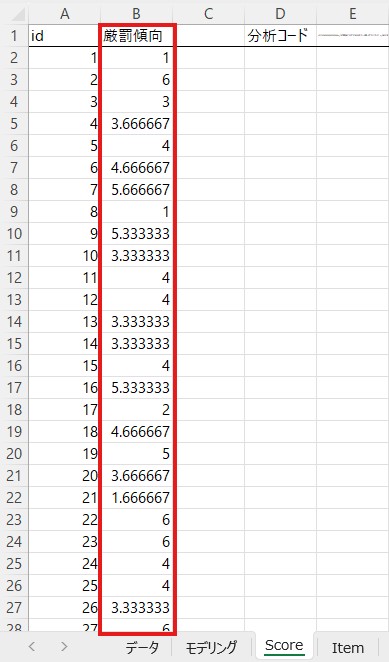
「Mean」だと何の平均値が分からないので名前を「厳罰傾向」に変えておきます。
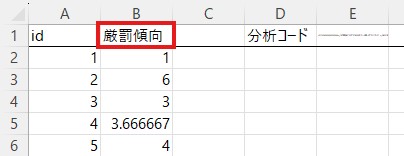
「厳罰傾向」の列全体を「データ」のシートに移す必要があるので、列全体をコピーします。
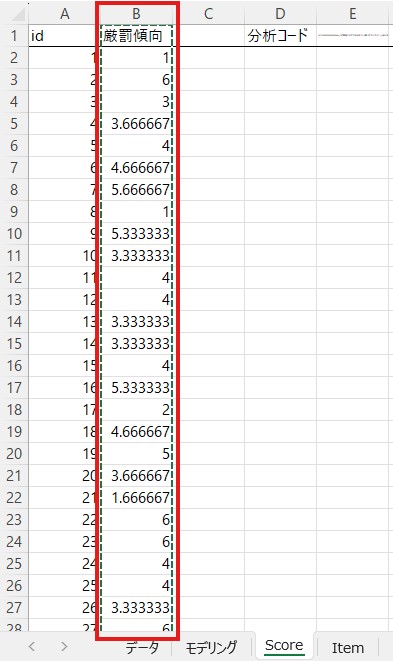
「データ」のシートに移動して、「ID」の右に貼り付けます。3列目で右クリックをし、「コピーしたセルの挿入」で「ID」の右に挿入できます。
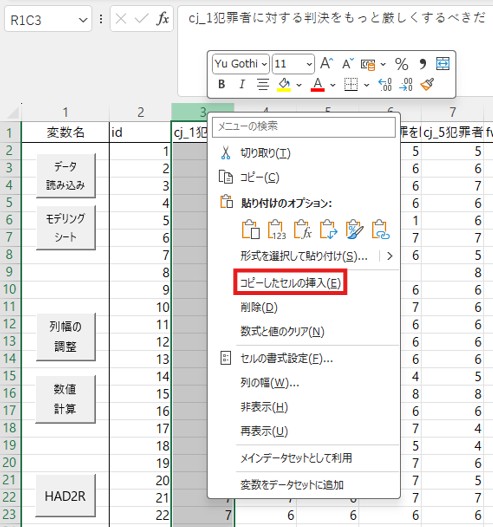
下の画像のようになれば完成です。
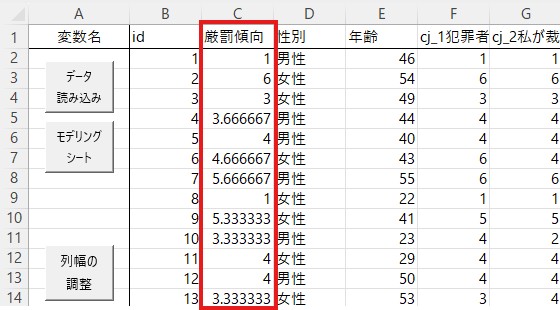
以上の作業を変数(因子)の数だけ繰り返してください。例として用いているデータには犯罪不安(foc1からfoc5)も含まれていますので、それもここまでと同様に処理し、下の画像のようにしてください。
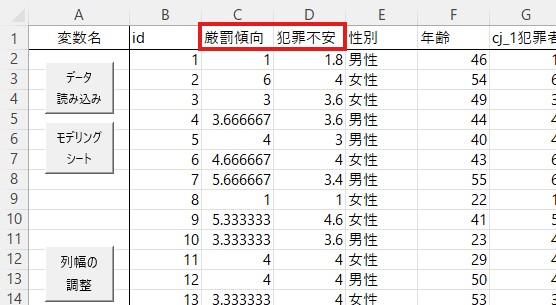
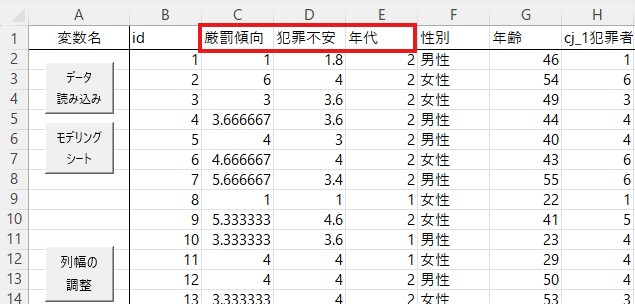
また、ここでは年代を独立変数として分散分析に用います。ただ、年齢はこのダミーデータでは連続変量として格納されています。ですので、分散分析の独立変数として扱うためには、離散変量に変換する必要があります。ここでは若年層(20・30代)、中年層(40・50代)、高齢層(60代以上)の3つのカテゴリーに分けましょう。エクセルのifelse関数を使うやり方などやり方は複数ありますので、慣れているやり方で変換してください。なお、HADでのやり方はこちらから確認できます。
以下のような状態になれば完成です。
3.記述統計
ここまでで分析に使用する合成変数は作成されましたが、分散分析の前には他にもしないといけないことがあります。分散分析と一緒によく行われる分析は、記述統計(平均値、標準偏差)の算出です。これらの情報はメタ分析の際にも必要になりますので、特段の事情がない限り論文には含めておくべきでしょう。
平均値と標準偏差
「データ」のシートで「データ読み込み」をクリックしたうえで、平均値と標準偏差を求めたい変数を「使用変数」の横に貼り付けます。

「分析」を左クリックしてください。

表示されたポップアップ画面で、左上の方にある「要約統計量」にチェックを入れてください。

右下にある「OK」を左クリックしてください。
「Summary」というシートが新たに作成されれば成功です。
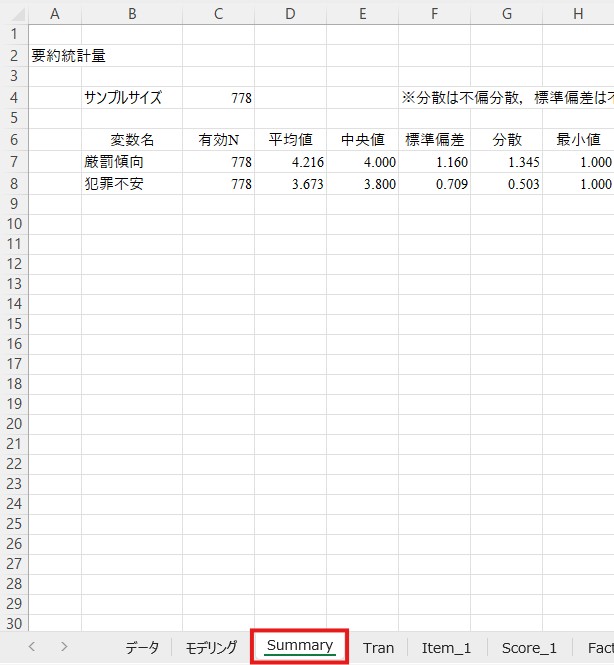
「平均値」と「標準偏差」の列にそれぞれの値が表示されています。たとえばここでは厳罰傾向の平均値は4.244、標準偏差は1.100であることが分かります。

4.分散分析の実行
ここまでの処理を行ってようやく分散分析を行うことができます。
まず分散分析に投入する変数を「使用変数」の横にコピペします。ここで重要なのは順番で、群分けのために使われる変数は一番右に置く必要があります。ここの分析では、厳罰傾向と犯罪不安が年代ごとに異なるのかを知りたいわけですので、「群分けのために使われる変数」は年代になります。これを一番右に置くようにしてください。

「分析」を左クリックしてください。

表示されたポップアップ画面で、左下の方にある「平均の差の検定」にチェックを入れてください。その下にある「対応なし」と「対応あり」については変えなくて大丈夫です。
「OK」を左クリックしてください。
従属変数の数だけ「Anova」というシートが作成されます。ここでは厳罰傾向と犯罪不安という2つの従属変数がありますので、「Anova1」(厳罰傾向の結果)、「Anova2」(犯罪不安の結果)の2つのシートが新たに作成されれば成功です。
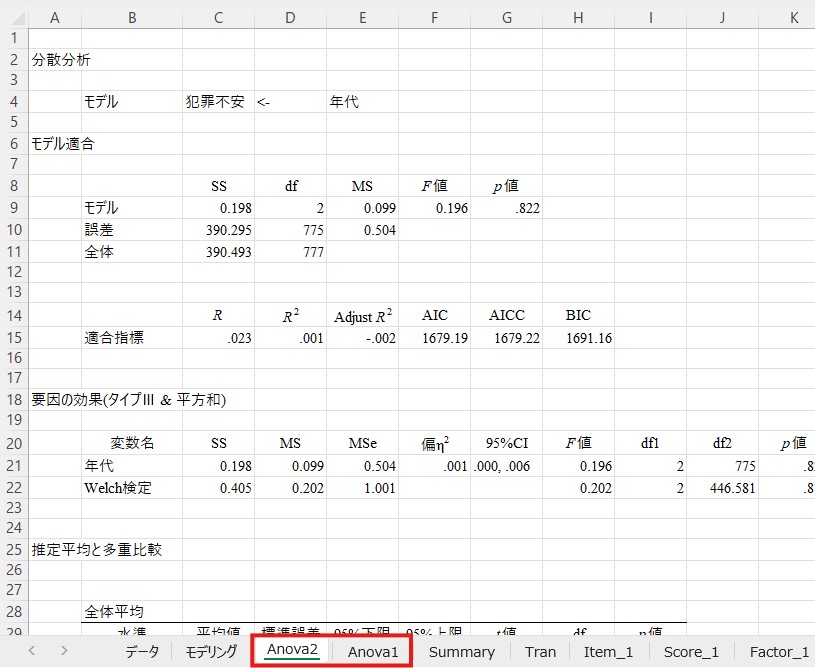
結果の読み方
分散分析では、①モデル全体の有意性の確認、②(モデル全体が有意であった場合には)個別のグループ間の差の検討(心理学では「多重比較」と呼ばれます)という順番で分析を進めます。①モデル全体の有意性の確認では、グループ間のどこかに差があるかをチェックします。したがって、①の段階で有意にならなければ②に進む必要はありません。他方、①で有意になった場合でも、具体的にどこに差があるかは分かりません。そのため、②の段階でどこに差があるのかを特定する必要があります。
厳罰傾向の結果
上の読み方に沿って、まず厳罰傾向に関する結果(「Anova1」のシート)を見てみましょう。①に対応する結果は、上の方にある「要因の効果」のp値で確認することができます。ここで「年代」のp値は.010になっています。多くの分析と同じく、p値が0.05以下であった場合には有意、0.05を超える場合には有意でないと判断します。したがって、厳罰傾向に対する年代の効果は有意ということになります。別の言い方をすれば、年代のグループのどこか同士に差があることが分かったということです。
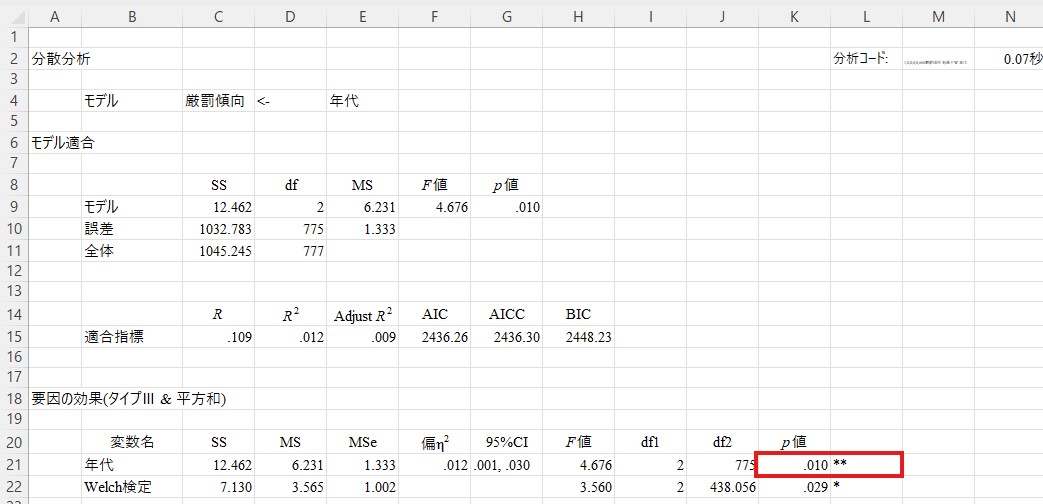
そこで、②の段階に進み、具体的にどこに差があるのかを検討します。それに対応する結果は、少し下の「推定平均と多重比較」の欄に書かれています。この中の「多重比較」という表には、水準(ここでは年代です)ごとの差の検定が行われています。ここでは「1」=「若年層」、「2」=「中年層」、「3」=「高齢層」でコーディングされていますので、「1-2」の行は「若年層と中年層の比較」、「1-3」の行は「若年層と高齢層の比較」、「2-3」は「中年層と高齢層の比較」になります。
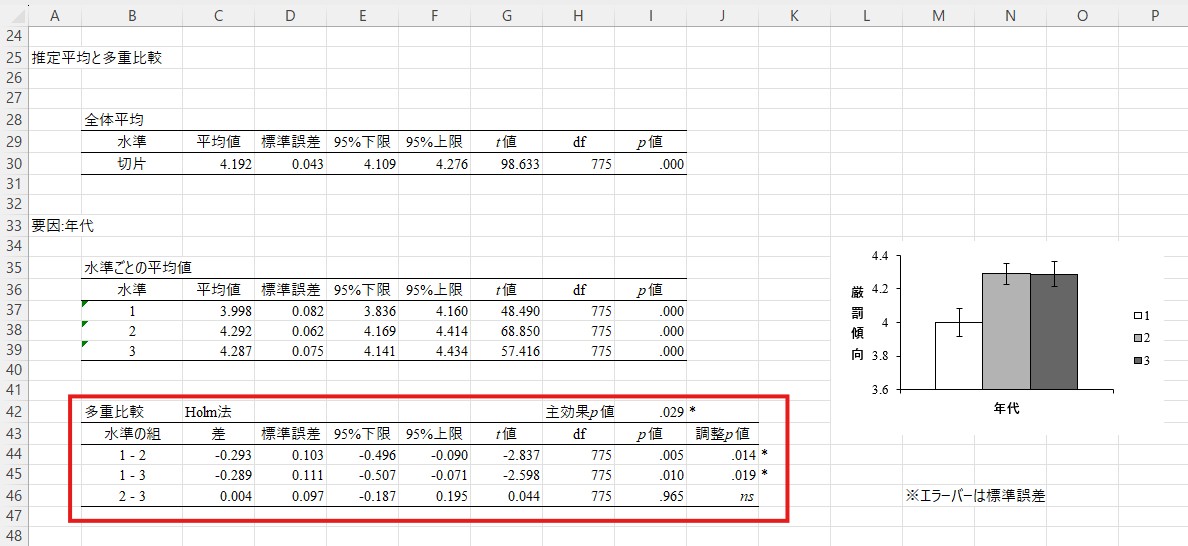
それぞれの組み合わせが有意かどうかを判断するには、表の一番右の「調整p値」の列を確認します。①の段階と同じく、.05以下であれば有意、.05を上回っていれば有意でないと判断します。ここで「1-2」の調整p値は.014、「1-3」の調整p値は.019、「2-3」の調整p値はns(non-significant=非有意の略です)となっていますので、「1-2」と「1-3」の差は有意であるのに対して、「2-3」の差は有意でないということになります。つまり、若年層は中年層および高齢層と比べて有意に厳罰的でない(逆に言えば、中年層と高齢層は若年層と比べて有意に厳罰的である)とまとめられます。
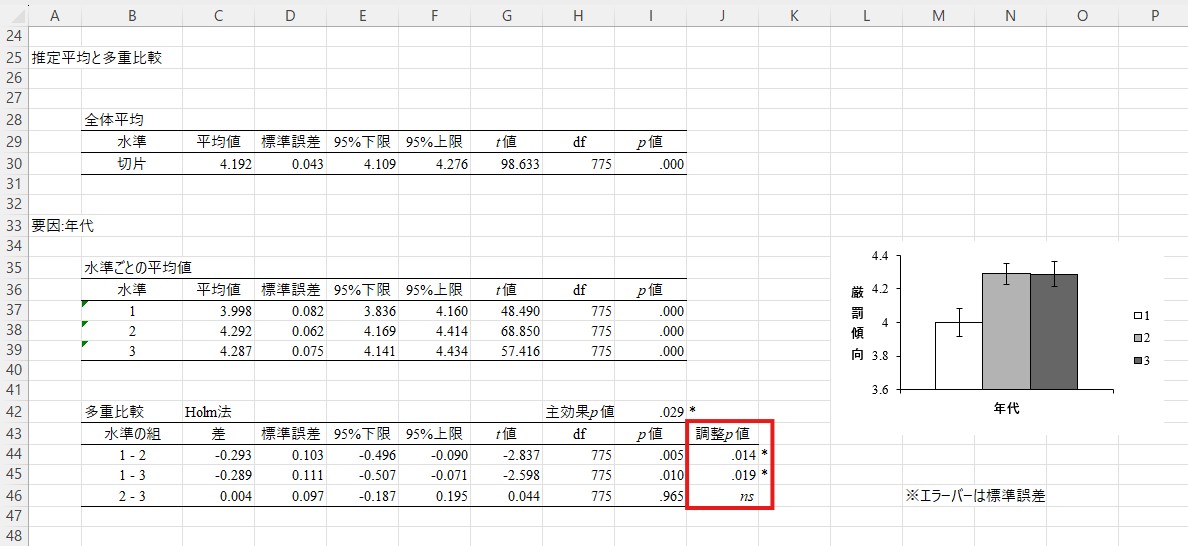
分かりにくい場合は、少し右上にある図も参考になります。これを見ると、「1-2」と「1-3」の間の差は大きいが、「2-3」の間の差はほとんどないことが見て取れるかと思います。
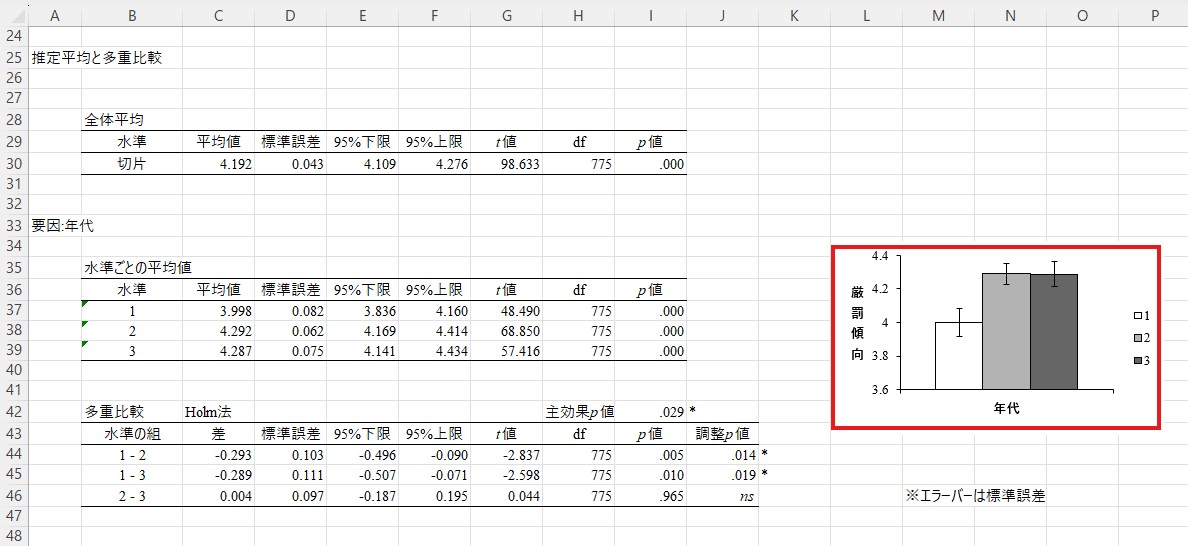
犯罪不安の結果
次に、犯罪不安に関する結果(「Anova2」のシート)も見てみましょう。「要因の効果」の中にある「年代」のp値を見てみると.822になっています。これは.05を上回っていますので、年代の効果は有意でないということになります。別の言い方をすれば、回答者の年代によって犯罪不安に差があるとはいえないことが分かりました。
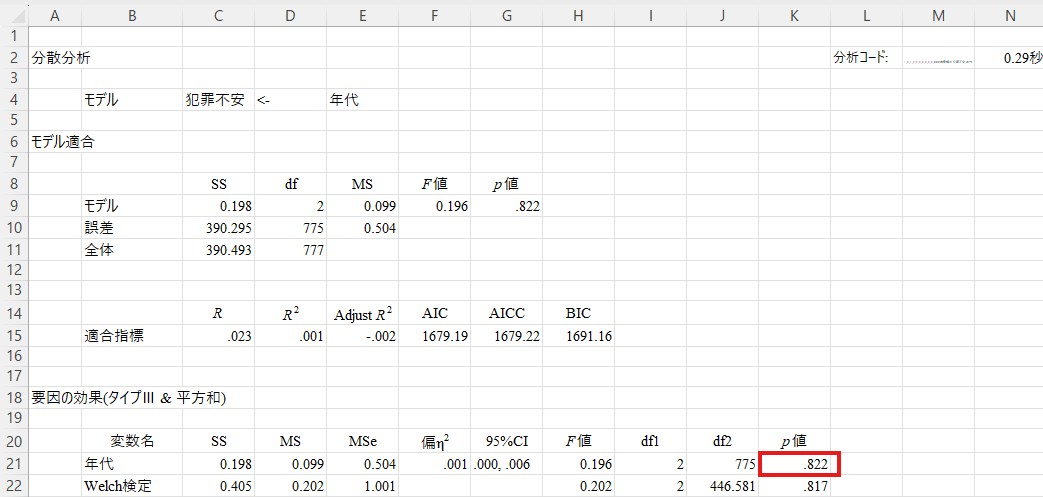
①の段階で有意にならなかった(つまり、「グループ間のどこかに差があるとはいえない」という結果になった)わけですので、具体的にどこに差があるかを知るための②の段階には進まず、分析はここで打ち切りです。
5.表の作成
ここまでで分析が終わりましたので、論文上で報告するための表を作成します。ここまでの分析をまとめたHADのファイルはこちらから、エクセルの表の見本はこちらからダウンロードできます。
ここまで行ってきたような分析の結果を報告する際には、記述統計の結果と分散分析の結果を報告する必要がありますが、これらは1つの表にまとめられます。また、自分で作った尺度(つまり先行研究がない尺度)を使っており因子分析を行った場合には、因子分析の結果も報告する必要があります。本データで使われているのは実際には因子分析をする必要のないデータですが、参考のために表を作成しておきます。分散分析の表の作り方はかなりややこしいので、最初に因子分析の表を示し(Table 1)、その後に分散分析の表について説明します(Table 2)。
表の効率的な作り方は人それぞれだと思いますので、見本を参考にしながらご自身で作成してください。以下ではHADの出力と表の対応のみを記載いたします。
因子分析
《表》

《HADの出力》
記述統計と分散分析
分散分析の表では左側に記述統計(平均値と標準偏差)をまとめ、右側に分散分析の結果をまとめることが多いかと思いますので、それに沿って作成します。
また、分散分析の結果では、分析全体が有意かに関する結果と、個別の組み合わせが有意かに関する結果をまとめる必要があります。より問題になるのは、個別の組み合わせの結果です。これについては大きく分けると、①アルファベットの組み合わせで示す方法と、②「<」で表示する方法があります。以下それぞれ示します(あくまで一例です)。
①アルファベットの組み合わせで示す方法
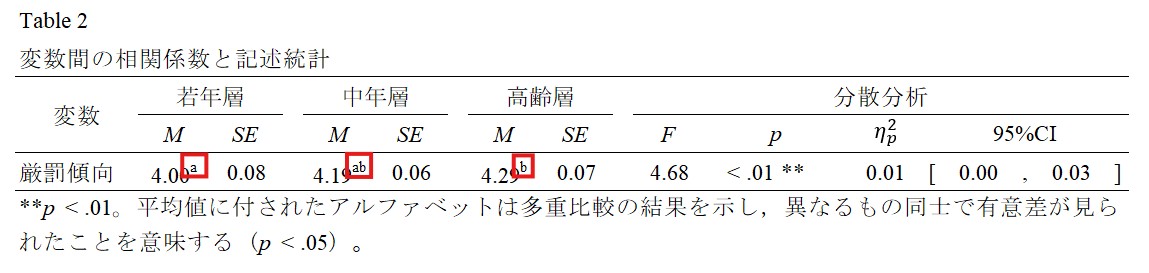
この方法では、アルファベットを組み合わせて多重比較の結果を表示します。異なるアルファベットは有意差があること、同じアルファベットは有意差がないことを示します。たとえば、今回の結果では、若年層と中年層の間には有意差がありますので若年層にはa、中年層にはbという異なるアルファベットを付すことで有意差があることを示します。これに対して、中年層と高齢層の間には有意差がありますので、両方にbという同じアルファベットを付すことで有意差がないことを示します。
《表》

《HADの出力1》

《HADの出力2》
なお、今回の場合は表記がしやすいパターンですが、若年層と中年層および中年層と高齢層には有意差がないが若年層と高齢層には有意差がある、というような面倒な表記しにくいパターンもあります。そうした場合にはアルファベットを二つ重ね、若年層にa、中年層にab、高齢層にbを付すことで表記します。こうすれば、若年層と中年層はa、中年層と高齢層はbという同じアルファベットを共有しているため有意差がないことが示せる一方、若年層と高齢層はaとbという異なるアルファベットが付されているため有意差があることが示せるからです。下画像のような形です。
②「<」で示す方法
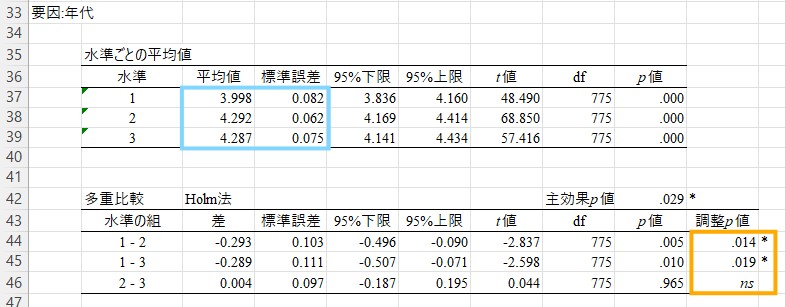
この方法では、「<」を使って多重比較の結果を表示します。「<」でつながれている水準同士は有意差があることを示し,「,」でつながれている水準同士は有意差がないことを示します。たとえば、今回の結果では、若年層と中年層の間には有意差がありますので若年層と中年層は「若年層 < 中年層」のように「<」でつなぎます。これに対して、中年層と高齢層の間には有意差がありますので、「,」でつなぎます。
《表》

《HADの出力1》

《HADの出力2》
6.論文の記述
表が作成できたら最後に文章を記述します。以下はここまでの分析の結果の書き方の一例ですが、絶対的に正しい正解はありませんので、他の論文も参考にしながら自分なりの書き方を見つけてください。
変数の合成:因子分析の場合
厳罰傾向を測定する5項目について探索的因子分析を行った。まず固有値の減衰状況を確認したところ,2.59, 0.25, 0.16と,明確に1因子構造が示唆される結果であったため,1因子解を指定して分析を行った。その結果,Table 1に示される通り,すべての項目の因子負荷量は.40以上であった。そのため,全項目の平均値を算出し,以後の分析に使用した。
変数の合成:信頼性係数の場合
厳罰傾向を測定する5項目についてCronbachのα係数を算出したところ,その値はα = .92であり,十分な内的一貫性が確認された。そのため,全項目の平均値を算出し,以後の分析に使用した。
記述統計と分散分析
回答者の年代を独立変数,厳罰傾向と犯罪不安を従属変数とした1要因3水準(年代:若年層,中年層,高齢層)の参加者間の分散分析を行った
。
その結果,Table 2に示される通り,年代の効果は有意であった(F(2, 775) = 4.68, p < .01, 偏η2 = 0.01, 95%CI [0.00, 0.03])
。
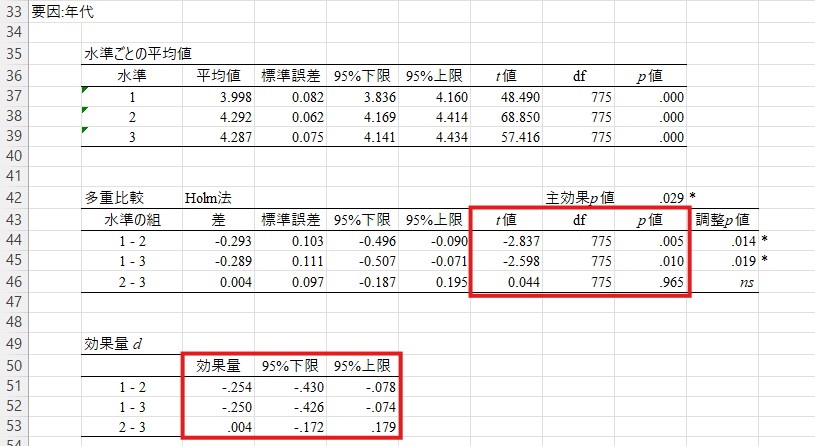
そこで多重比較(Holm法)を行ったところ,若年層(M = 4.00, SE = 0.08)と中年層(M = 4.29, SE = 0.06)の間には有意差が見られた(t(775) = -2.84, p < .01, d = -.25, 95%CI [-.43, -.08])。また,若年層と高齢層(M = 4.29, SE = 0.07)の間にも有意差が見られた(t(775) = -2.60, p = .01, d = -.25, 95%CI [-.43, -.07])。他方,中年層と高齢層の間には有意差が見られなかった(t(775) = 0.04, p = .97, d = .00, 95%CI [-.17, .18])
犯罪不安についても同様に分散分析を行ったが,年代の水準間で有意な差は見られなかったF(2, 775) = 0.20, p = .82, 偏η2 = 0.00, 95%CI [0.00, 0.01])。
赤でハイライトした部分では、分析全体の枠組みが記述されています。ここでは要因(独立変数)は「年代」の1つですので「一要因」、「若年層・中年層・高齢層」の3つのグループがありますので「3水準」、各水準に含まれるデータは異なる回答者から得られたデータですので「参加者間」となります。
緑でハイライトした部分では、分散分析の結果が記述されており、どこかの水準間に差があるかが検討されています。書かれている数値は表に記述されているものと同じです。厳罰傾向の場合は有意となったので多重比較に進み、犯罪不安の場合は有意とならなかったので多重比較には進まず打ち切っています。
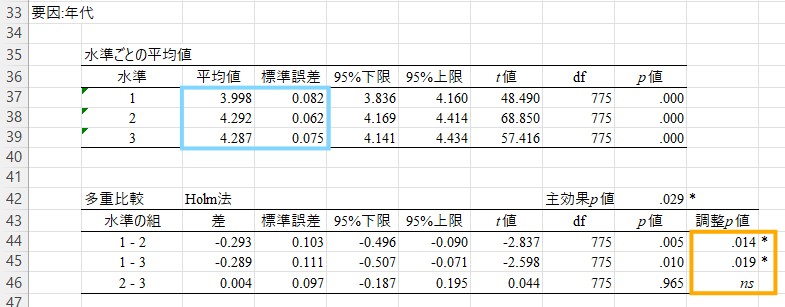
緑でハイライトした部分では、多重比較の結果が記述されています。「若年層」などの各水準の初出の箇所で記述統計(平均値と標準誤差)を記述して、記述統計とまとめています。また、組み合わせごとの比較の後には統計量(t値、p値など)をまとめています(可能ならこれらの値も表にまとめたいところですが、入れ込むのは中々難しいと思います)。これらの値は下記画像の赤で囲った部分に記述されています。
ページ上部に戻る